Сегодня мы подробно рассмотрим файл robots txt – что это такое, зачем он нужен и как с ним работать. Понятие термина robots txt описывается на множестве сайтов и блогов. Однако везде статьи данной тематики существенно отличаются друг от друга. А потому пользователи путаются в них, как рыба в сетях.

Содержание статьи:
- Файл Robots txt – что за страшный зверь?
- Что именно и как обрабатывает файл?
- Дерективы файла Robots txt – для каких целей они необходимы?
- Как создать файл robots txt: подробная инструкция
- Что такое Disallow?
- Allow — команда для направления роботов
- Host + в файл robots txt или как выбрать зеркало для вашего сайта
- Sitemap – что это такое и как работать с ней?
- Crawl-delay — если сервер слабый
- Clean-param — если имеет дублирование контента
- Какие символы используются в robots.txt
- Идеальный файл robots.txt: какой он?
- Как проверить файл robots.txt
- Как не стоит заполнять файл robots.txt: простые рекомендации
- Что мы узнали о файле robots txt
Файл Robots txt – что за страшный зверь?
Robots.txt представляет собой файл. Это стандартный текстовый документ, сохраненный с применением кодировки UTF-8. Он создается специально для работы с такими протоколами, как:
- https;
- https;
- FTP.
Файл несет в себе важную функцию – он нужен для того, чтобы показывать поисковому роботу, что конкретно подлежит сканированию, а что закрыто от сканирования.
Обратите внимание! Крайне важно, чтобы файл сохранялся в кодировке UTF-8. Если это условие будет не выполнено, поисковые роботы неправильно интерпретируют команды, заложенные в документе.
Все правила, требования, рекомендации, которые указаны в robots.txt актуальны лишь для конкретного хоста, а также протокола и номера порта, где непосредственно и находится описываемый нами файл.
Кстати, сам robots.txt находится в корневом каталоге и представляет собой стандартный текстовый документ. Его адрес следующий https://admin.com /robots.txt., где admin.com – имя вашего сайта.
В прочих файлах ставится специальная пометка Byte Order Mark или ее еще называют аббревиатурой ВОМ. Данная пометка представляет собой юникод-символ – он требуется для того, чтобы установить четкую последовательность считываемой информации в байтах. Кодовый символ – U+FEFF.
А вот в начале нашего robots.txt пометка последовательной считываемости пренебрегается.
Важно! Следите за «весом» файла robots.txt. Так, поисковая система Google требует, что его размер не превышал 500 килобайт.
Отметим непосредственно технические характеристики robots.txt. В частности, упоминания заслуживает тот факт, что файл являет описание, представляемой в BNF-форме. И применяются правила RFC 822.
Что именно и как обрабатывает файл?
Считывая указанные в файле команды, роботы поисковых систем получают от следующие команды к исполнению (одну из нижеперечисленных):
- сканирование только отдельных страниц – это называется частичный доступ;
- сканирование всего сайта в целом – полный доступ;
- запрет на сканирование.
Проводя обработку сайта, роботы получают определенные ответы, которые могут быть следующими:
- 2хх – сканирование сайта было выполнено успешно;
- 3хх – робот переходит по переадресации, пока ему не удалось получить другой ответ. В большинстве случаев для этого необходимо пять попыток, дабы найти ответ, который будет отличаться от 3хх. Если за пять попыток ответ не получен, будет зафиксирована ошибка 404;
- 4хх – робот уверен, что следует провести сканирование всего сайта;
- 5хх – такой ответ расценивается, как временная ошибка сервера, а проведение сканирования запрещается. Поисковый робот будет «стучаться» к файлу так долго, пока им не будет получен ответ. При этом робот от Google проводит оценку корректности или некорректности ответов. В данном случае следует говорить о том, что если вместо традиционной ошибки 404 получен ответ 5хх, то в данной ситуации робот обработает страницу с ответом 404.
Обратите внимание! На момент написания статья так еще и не было понятно, как именно проводится обработка файла robots.txt, который в момент обращения к нему поисковых роботов недоступен из-за того, что у сервера возникают проблемы с доступом к интернету.
Дерективы файла Robots txt – для каких целей они необходимы?
К примеру, есть ситуации, когда необходимо ограничить посещение роботами:
- страниц, на которых располагает личная информация владельца;
- страниц, на которых размещены те или иные формы для передачи информации;
- зеркал сайта;
- страниц, на которых помещаются результаты поиска и т.д.
Обратите внимание! Даже если вы ограничите посещение страницы поисковыми роботами, она может в конечном итоге появится в результатах поисковой выдачи, но только в том случае, если на нее имеется ссылка либо на вашем сайте, либо на каком-то другом ресурсе.
На схеме ниже представлено, как поисковые роботы видят отдельные страницы сайта при наличии robots.txt и при его отсутствии.
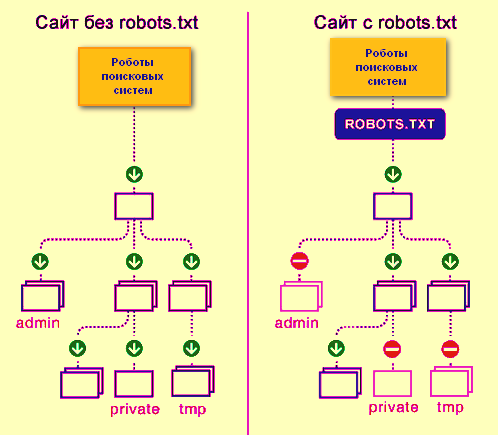
Если не использовать дерективы файла robots txt, то все данные, информация, которые не предназначены для людей, в конечном итоге будет оказываться в результатах поисковой выдачи, от чего будете страдать не только вы, как владелец сайта, но и сам сайт!
Как создать файл robots txt: подробная инструкция
Для создания такого файла можете использовать фактически любой редактор текста, например:
- Notepad;
- Блокнот;
- Sublime и др.
В этом «документе» описывается инструкция User-agent, а также указывается правило Disallow, но есть и прочие, не такие важные, но необходимые правила/инструкции для поисковых роботов.
User-agent: кому можно, а кому нет
Наиболее важная часть «документа» — User-agent. В ней указывается, каким именно поисковым роботам следует «посмотреть» инструкцию, описанную в самом файле.
В настоящее время существует 302 робота. Чтобы в документе не прописывать каждого отдельного робота персонально, необходимо указать в файле запись:
User-agent: *

Такая пометка указывает на то, что правила в файле ориентированы на всех поисковых роботов.
У поисковой системы Google основной поисковый робот Googlebot. Чтобы правила были рассчитаны только на него, необходимо в файле прописать:
User-agent: Googlebot_

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
У Яндекс основной поисковый робот Yandex и для него запись в файле будет выглядеть следующим образом:
User-agent: Yandex

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
Прочие специальные поисковые роботы
- Googlebot-News — используется для сканирования новостных записей;
- Mediapartners-Google — специально разработан для сервиса Google AdSense;
- AdsBot-Google — оценивает общее качество конкретной целевой страницы;
- YandexImages — проводит индексацию картинок Яндекс;
- Googlebot-Image — для сканирования изображений;
- YandexMetrika — робот сервиса Яндекс Метрика;
- YandexMedia — робот, индексирующий мультимедиа;
- YaDirectFetcher — робот Яндекс Директ;
- Googlebot-Video — для индексирования видео;
- Googlebot-Mobile — создан специально для мобильной версии сайтов;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, он проводит сканирование не только постов, но даже комментарие;
- YandexDirect — разработан для того, чтобы анализировать наполнение партнерский сайтов Рекламной сети. Это позволяет определить тематику каждого сайта и более эффективно подбирать релевантную рекламу;
- YandexPagechecker — валидатор микроразметки.
Перечислять прочих роботов не будем, но их, повторимся, всего насчитывается более 300-т. Каждый из них ориентирован на те или иные параметры.
Что такое Disallow?
Disallow – указывает на то, что именно не подлежит сканировании на сайте. Чтобы весь сайт был открыт для сканирования поисковыми роботами, необходимо вставить запись:
User-agent: *
Disallow:

А если вы хотите, чтобы весь сайт был закрыт для сканирования поисковыми роботами, в файле введите следующую «команду»:
User-agent: *
Disallow: /

Такая «запись» в файле будет актуальна в том случае, если сайт еще не полностью готов, вы планируете вносить в него изменения, но чтобы в нынешнем своем состоянии он не отображался в поисковой выдаче.
Обратите внимание! Однако эту команду следует снять, как только сайт будет окончательно сформирован. Хотя некоторые веб-мастера забывают об этом.
И еще несколько примеров, как прописать ту или иную команду в файле robots.txt.
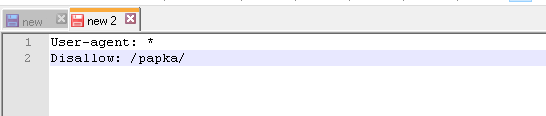
Чтобы роботы не просматривали конкретную папку на сайте:
User-agent: *
Disallow: /papka/
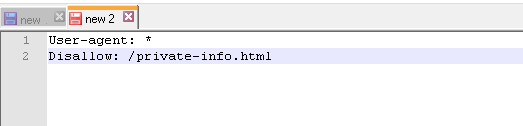
Чтобы закрыть от сканирования определенный URL:
User-agent: *
Disallow: /private-info.html
Чтобы закрыть от сканирования определенный файл:
User-agent: *
Disallow: /image/имя файла и его расширение

Чтобы закрыть от сканирования все файлы конкретного разрешения:
User-agent: *
Disallow: /*.имя расширение и значок $ (без пробела)

Allow — команда для направления роботов
Allow – эта команда дает разрешение на сканирования определенных данных:
- файла;
- директивы;
- страницы и т.д.
В качестве примера рассмотрим ситуацию, когда важно, чтобы роботы могли просмотреть лишь те страницы, которые начинаются с /catalog, а все остальное содержимое сайта подлежит закрытию. Команда в файле robots.txt будет выглядеть следующим образом:
User-agent: *
Allow: /catalog
Disallow: /
Обратите внимание! «Правила» Allow и Disallow отсортировываются в зависимости от длины префикса URL, в частности сортировка идет от наиболее маленького к наибольшему. Их применение осуществляется строго последовательно. Однако, если для одной страницы сайта будут актуальными сразу несколько правил, поисковый робот выберет последнее из них в отсортированном списке команд.
Host + в файл robots txt или как выбрать зеркало для вашего сайта
Внесение команды host + в файл robots txt является одной из нескольких обязательных задач, которые нужно сделать в первую очередь. Она предусмотрена для того, чтобы поисковый робот понимал, какое зеркало сайта подлежит индексации, а какое – не следует учитывать при проведении сканирования страниц сайта.
Кстати! Зеркалом сайта называют копию ресурса (точную или весьма близкую к основному сайту), доступ к которой возможен по нескольким адресам.
Такая команда позволит роботу избежать путаницы в случае обнаружения зеркала, а также понять, что является главным зеркалом ресурса – оно указывается в файле robots.txt.
При этом адрес сайта указывается без «https://», однако, если ваш ресурс работает на HTTPS, в таком случае соответствующая приставка должна быть обязательно указана.
Данное правило прописывается следующим образом:
User-agent: * (имя поискового робота)
Allow: /catalog
Disallow: /
Host: имя сайта 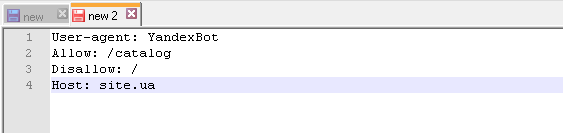
Если же сайт работает по протоколу HTTPS, команда будет прописана следующим образом:
User-agent: * (имя поискового робота)
Allow: /catalog
Disallow: /
Host: https:// имя сайта
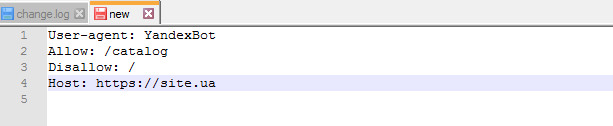
Sitemap – что это такое и как работать с ней?
Sitemap необходима для того, чтобы передать поисковым роботам информацию о том, что все URL-адреса сайта, открытые для сканирования и индексации, расположены по адресу https://site.ua/sitemap.xml.
Во время каждого посещения и сканирования сайта, поисковый робот будет изучать, какие именно изменения были внесены в данный файл, тем самым обновляя информацию о сайте в своей базе данных.
Вот как правильно прописать эти «команды» в файле robots.txt:
User-agent: *
Allow: /catalog
Disallow: /
Sitemap: https://site.ua/sitemap.xml.
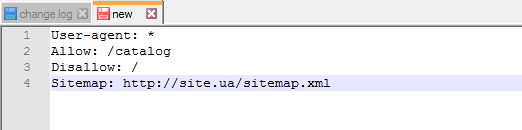
Crawl-delay — если сервер слабый
Crawl-delay необходимый параметр для тех сайтов, которые находятся на слабых серверах. С его помощью у вас есть возможность устанавливать конкретный период, через который будут загружаться страницы вашего ресурса.
Ведь слабые серверы провоцируют образование задержек во время обращения к ним поисковых роботов. Такие задержки фиксируются в секундах.
Вот пример, как прописывается данная команда:
User-agent: *
Allow: /catalog
Disallow: /
Crawl-delay: 3

Clean-param — если имеет дублирование контента
Clean-param – предназначен для того, чтобы «сражаться» с get-параметрами. Это необходимо для того, чтобы исключить вероятное дублирование контента, который в итоге будет доступен поисковым роботам по различным динамическим адресам. Подобные адреса появляются в том случае, если на ресурсе имеются разные сортировки или т.п.
К примеру, конкретная страница может быть доступна по следующим адресам:
- www.vip-site.com/foto/tele.ua?ref=page_1&tele_id=1
- www.vip-site.com/foto/tele.ua?ref=page_2&tele_id=1
- www.vip-site.com/foto/tele.ua?ref=page_3&tele_id=1
В подобной ситуации в файле robots.txt будет присутствовать следующая команда:
User-agent: Yandex
Disallow:
Clean-param: ref /foto/ tele.ua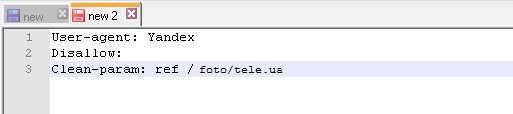
В данном случае параметр ref показывает, из какого именно места идет ссылка, а потому она прописывается непосредственно в самом начале, а только после этого прописывается оставшаяся часть адреса.
Какие символы используются в robots.txt
Чтобы не ошибиться при написании файла, следует знать все символы, которые используются, а также понимать их значение.
Вот основные символы:
/ — он необходим, чтобы закрыть что-то от сканирования поисковыми роботами. Например, если поставить /catalog/ — в начале и в конце отдельной директории сайта, то эта папка будет полностью закрыта от сканирования. Если же команда будет выглядеть, как /catalog, то на сайте окажутся закрытыми все ссылки на сайте, начало которых прописано, как /catalog.
* — указывается на любую последовательность символов в файле и устанавливается в конце каждого правила.
Например, запись:
User-agent: *
Disallow: /catalog/*.gif$

Такая запись говорить, что все роботам запрещено сканирование и индексирование файлов с расширением .gif, которые помещены в папку сайта catalog.
«$» — используется для того, чтобы ввести ограничения на действия знака *. К примеру, вам нужно наложить запрет на все, что находится в папке catalog, но также нельзя запрещать URL, в которых присутствует /catalog, необходимо сделать следующую запись:
User-agent: *
Disallow: /catalog?

— «#» — такой значок предназначен для комментариев, заметок, которые веб-мастер формирует для себя или прочих веб-мастеров, которые также будут работать с сайтом. Такой значок запрещает сканирование этих комментариев.
Выглядеть запись будет следующим образом (к примеру):
User-agent: *
Allow: /catalog
Disallow: /
Sitemap: https://site.ua/sitemap.xml.
#инструкции

Идеальный файл robots.txt: какой он?
Вот пример фактически идеального файла robots.txt, который подойдет если не для всех, то для многих сайтов.
User-agent: *
Disallow:
User-agent: GoogleBot
Disallow:
Host: https://имя сайта
Sitemap: https://имя сайта/sitemap.xml.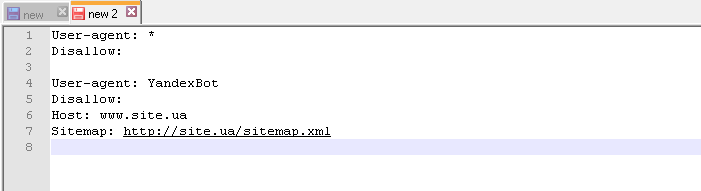
Давайте проанализируем, что представляет собой данный файл robots.txt. Итак, он позволяет индексировать все страницы сайта и весь контент, который там размещен. Также в нем указываются хост и карта сайта, благодаря чему поисковики будут видеть все адреса, открытые для индексирования.
Кроме того, отдельно указываются рекомендации для поисковых роботов Google.
Однако не стоит просто скопировать этот файл для своего сайта. Во-первых, для каждого ресурса следует предусмотреть отдельные правила и рекомендации. Они напрямую зависят от платформы, на которой вы создали сайт. Поэтому помните все правила заполнения файла.
Как проверить файл robots.txt
Чтобы убедиться, что файл создан правильно, для его проверки воспользуйтесь сервисами инструментов веб-мастеров от Яндекс и Google.
Сделать это весьма просто – достаточно просто указать исходный код вашего файла, поместив его в специальную форму, а также указать сайт, который вы собираетесь проверить.
Как не стоит заполнять файл robots.txt: простые рекомендации
Нередко веб-мастера допускают ошибки – зачастую, досадные. Чаще всего причина таких ошибок кроется в банальной невнимательности. Мы представим вам несколько примеров таких ошибок, а также укажем, как должно быть правильно.
Ошибки в инструкциях
Неправильно:
User-agent:/
Disallow: YandexBot
Правильно:
User-agent: YandexBot
Disallow: /

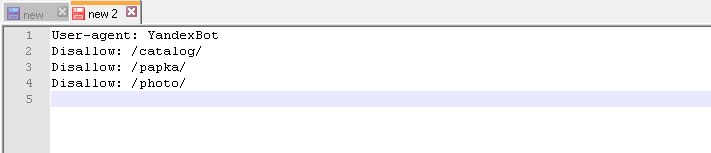
В одной инструкции указано несколько папок
Неправильно:
User-agent: YandexBot
Disallow: /catalog/ /papka/ /photo/
Подобные инструкции приведут к тому, что поисковые роботы просто запутаются, что именно подлежит индексации, а что нет. То ли первая папка, то ли последняя. Поэтому нужно каждое правильно прописывать отдельно.
User-agent: YandexBot
Disallow: /catalog/
Disallow: /papka/
Disallow: /photo/
Прочие ошибки
1. Ошибки в названии файла. Название – только robots.txt, но не Robots.txt, не ROBOTS.TXT и никак по-другому!
2. Правило User-agent обязательно должно быть заполненным – нужно указывать, либо какой конкретно робот должен учитывать его, либо вообще все.
3. Наличие лишних знаков.
4. Присутствует в файле страниц, которые не должны индексироваться.
Что мы узнали о файле robots txt
Файл Robots txt – играет важную роль для каждого отдельного сайта. В частности, он необходим, чтобы устанавливать определенные правила для поисковых роботов, а также продвигать свой сайт, компанию.
Кроме того, данный файл открывает широкое поле для экспериментов, но проводить их следует только в том случае, если вы досконально разобрались, как именно прописывать инструкции!
Подробнее о файле Robots txt и о создании сайтов в целом, вы можете узнать придя на мой бесплатный 4-х дневный тренинг по созданию сайтов с нуля, где я дам пошаговую инструкцию. Я помогу вам воплотить в жизнь свою мечту. Единственное, о чем хотел бы вас предупредить – будьте готовы к тому, что вам придется много работать. Успех просто так никому не дается!






Добавить комментарий